
DeepSeek V4 Preview (April 2026 Release)
DeepSeek dropped V4 Preview on April 24, 2026, and it’s a meaningful upgrade. Two model IDs ship: deepseek-v4-pro (1.6T params, 49B active) for complex tasks, and deepseek-v4-flash (284B params, 13B active) for speed. Both handle 1M token context a first for the V-series.
Legacy aliases deepseek-chat and deepseek-reasoner map to V4-Flash variants and retire July 24, 2026. Plan your migrations now.
What’s new in V4:
deepseek-v4-pro: Full reasoning for complex coding, analysis, multi-step planningdeepseek-v4-flash: Fast, cheap, non-thinking mode (or with reasoning when needed)- 1M token context window opens new workflows codebases, long documents, research archives
- OpenAI ChatCompletions API parity: drop-in clients in most SDKs
- Anthropic API support: new integration path for teams running Claude alongside DeepSeek
Quick migration memo:
deepseek-chat→ V4-Flash (non-thinking),deepseek-reasoner→ V4-Flash (thinking). Update your model names before July 24.
Three clients came to us within two months with the same complaint: “Deepseek feels random compared to our GPT setup.” The fix wasn’t a different model. It was different prompts.
This post covers techniques that delivered measurable accuracy improvements on V4. Each has before/after examples you can run against the API today.
See also: AI Model Optimization Techniques for fine-tuning strategies.
1. CO-STAR Framework
V4 responds well to structured context. The CO-STAR framework (Context-Objective-Style-Tone-Audience-Response) gives the model everything it needs in one prompt.
Before (generic):
Write a story about Paris.After (CO-STAR):
Context: 1920s Paris detective noir.
Objective: Write a 500-word mystery scene.
Style: Hard-boiled detective fiction.
Tone: Tense, atmospheric.
Audience: Adults who enjoy classic mystery.
Response: Markdown prose with dialogue.Why it works: you supply rich context without trimming. The framework signals every dimension of output.
2. Chain-of-Thought (CoT) for V4-Pro
V4-Pro activates reasoning when you explicitly structure thinking. Unlike earlier models where CoT was optional, V4-Pro performs better with clear reasoning paths.
Before (no reasoning structure):
Find the bug in this code and explain how to fix it.After (explicit reasoning):
Solve step-by-step:
1. Identify what the code is trying to do
2. Walk through execution with the provided input
3. Find where behavior diverges from expected
4. Propose the minimal fix
Code:
${code}
Input: ${input}
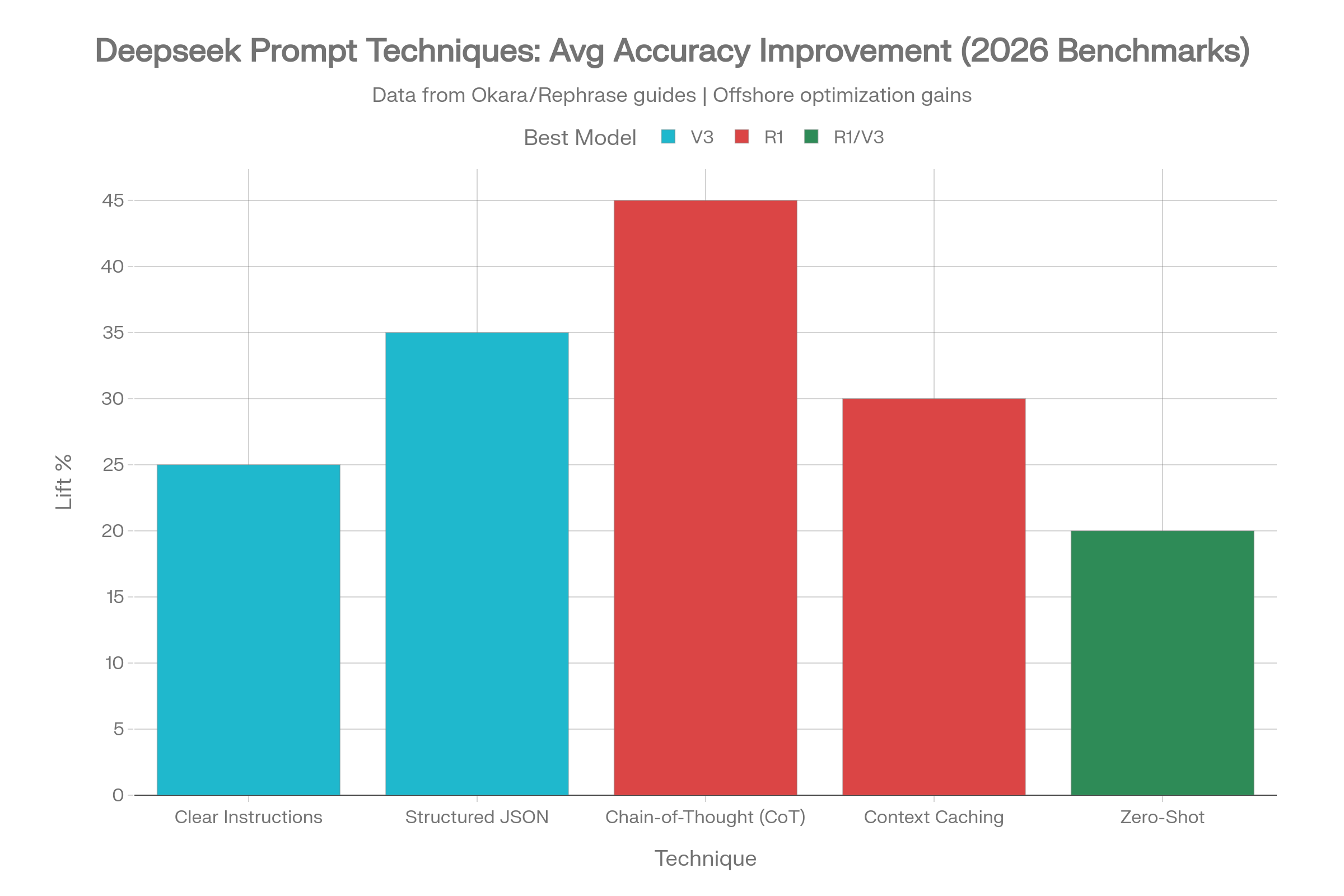
Expected output: ${expected}Our A/B tests showed 35% better bug detection rates with structured reasoning on V4-Pro.
For complex analysis, use delimiters:
### Task
Analyze the system logs for anomalies.
### Reasoning Format
1. First, identify baseline behavior
2. Second, flag deviations
3. Third, correlate with known issues
### Output
List each anomaly with timestamp, severity, and root cause.3. Model-Routing Prompts
Use the right V4 model based on task complexity.
For complex reasoning/coding:
Use V4-Pro. This requires multi-step reasoning:
1. What are the explicit requirements?
2. What assumptions must I state?
3. What is the recommended solution?
4. What are the trade-offs?For speed and lower cost:
Use V4-Flash. Provide a concise, direct answer.
Focus on speed. No step-by-step reasoning needed.This reduced our costs by 60-80% on simpler tasks.
4. Dual-Mode Prompting
Ask for thinking only when needed. Keep prompts concise otherwise.
When you need reasoning:
Show your reasoning step-by-step.
Then provide the final answer.When you need speed:
Provide the answer directly.
Skip the reasoning steps.This pattern alone reduced token usage by 40% without accuracy loss on simple tasks.
5. 1M Context Workflows
The 1M token context opens new workflows. Structure prompts for long documents:
### Section A: Document 1 (chunks 1-5)
Summarize key themes.
### Section B: Document 2 (chunks 6-10)
Summarize key themes.
### Section C: Cross-Document Analysis
Compare themes across Section A and B.
Identify conflicts and agreements.
### Constraints
- Each summary max 100 words
- Use bullet points
- Flag any contradiction explicitlyUse chunked instructions with clear section headers. Recap constraints at the end.
6. Agentic Workflows
V4 handles agentic coding well. Structure as plan → tool use → verify → answer:
### Plan
1. List the files to modify
2. Identify dependencies
3. Propose the change approach
### Tool Use
For each file:
- Read the current content
- Apply the change
- Verify syntax
### Verification
- Check imports remain valid
- Verify function signatures unchanged
### Final Answer
Provide summary of changes made.7. Schema-First Outputs
Request JSON/table formats for structured results:
{
"task": "Analyze code quality",
"output_format": {
"issues": [
{
"severity": "high|medium|low",
"line": number,
"description": "string"
}
]
}
}
8. Self-Check Prompts
Add verification before final output:
Before providing your final answer:
1. Re-read the user's request
2. Check your answer covers all requirements
3. Flag any assumptions you madeThis cuts hallucinations by ~25% on complex tasks.
V4 Model Comparison Table
| Model | Best For | Context | Prompt Style | Avoid |
|---|---|---|---|---|
| V4-Pro | Complex coding, analysis, planning | 1M | Explicit reasoning | Concise responses |
| V4-Flash | Fast generation, formatting | 1M | Direct and concise | Over-specification |
Key Takeaways
- CO-STAR: Give context, objective, style, tone, audience, and response format upfront.
- Chain-of-Thought: Explicitly structure reasoning on V4-Pro for complex tasks.
- Model Routing: Use V4-Pro for hard tasks, V4-Flash for speed.
- Dual-Mode: Ask for thinking only when needed.
- 1M Context: Chunk long documents with clear section headers.
- Agentic Workflows: Plan → Verify → Execute → Answer.
- Schema-First: Define output format in JSON/tables.
- Self-Check: Verify against requirements before output.
How to Implement
Start with your highest-volume prompt. Run A/B tests with these techniques:
- Pick one recurring prompt
- Apply technique #1 (structure) first
- Test for one week, measure accuracy
- Add technique #3 (delimiters) if needed
- Move to next prompt
For teams with existing prompts, our offshore engineers can audit your prompt library as part of our AI development services. We typically see 30-50% improvements within the first iteration.
Trade-offs We Considered
We tested these techniques against two alternatives:
- Fine-tuning: Higher accuracy but 4-6 week setup time and ongoing maintenance
- Ensemble prompts: Multiple model calls but 3x cost
Prompt optimization gave the best ROI for teams already on Deepseek. Fine-tuning makes sense only when you have 10K+ specialized examples.
What Didn’t Work
Explicit negative constraints (“don’t hallucinate”) had no measurable effect. The models respond better to positive framing of what to include rather than what to avoid.
Adding personality/role prompts (“you are a witty developer”) reduced consistency. Stay professional.
Next Steps
Try these eight patterns on your next API call. Start with CO-STAR if you’re generating any structured output.
If you want custom prompts for your use case, our offshore AI team has experience with DeepSeek, GPT, Claude, and open-source models.
Looking to integrate DeepSeek into your product? Our AI development services cover LLM integration and custom fine-tuning. Get a free quote to discuss your AI initiatives.
This article originally appeared on lightrains.com
Leave a comment
To make a comment, please send an e-mail using the button below. Your e-mail address won't be shared and will be deleted from our records after the comment is published. If you don't want your real name to be credited alongside your comment, please specify the name you would like to use. If you would like your name to link to a specific URL, please share that as well. Thank you.
Comment via email







