
Two weeks before a Fortune 500 product launch, we told a client to scrap their fine-tuned model and rebuild with RAG instead. They lost eight weeks and $180K. The fine-tuned model still hallucinated on new product features. RAG would have handled updates by reindexing documents.
Enterprise AI teams waste months and serious money betting on the wrong strategy. This guide gives you real numbers so you can stop guessing and start building.
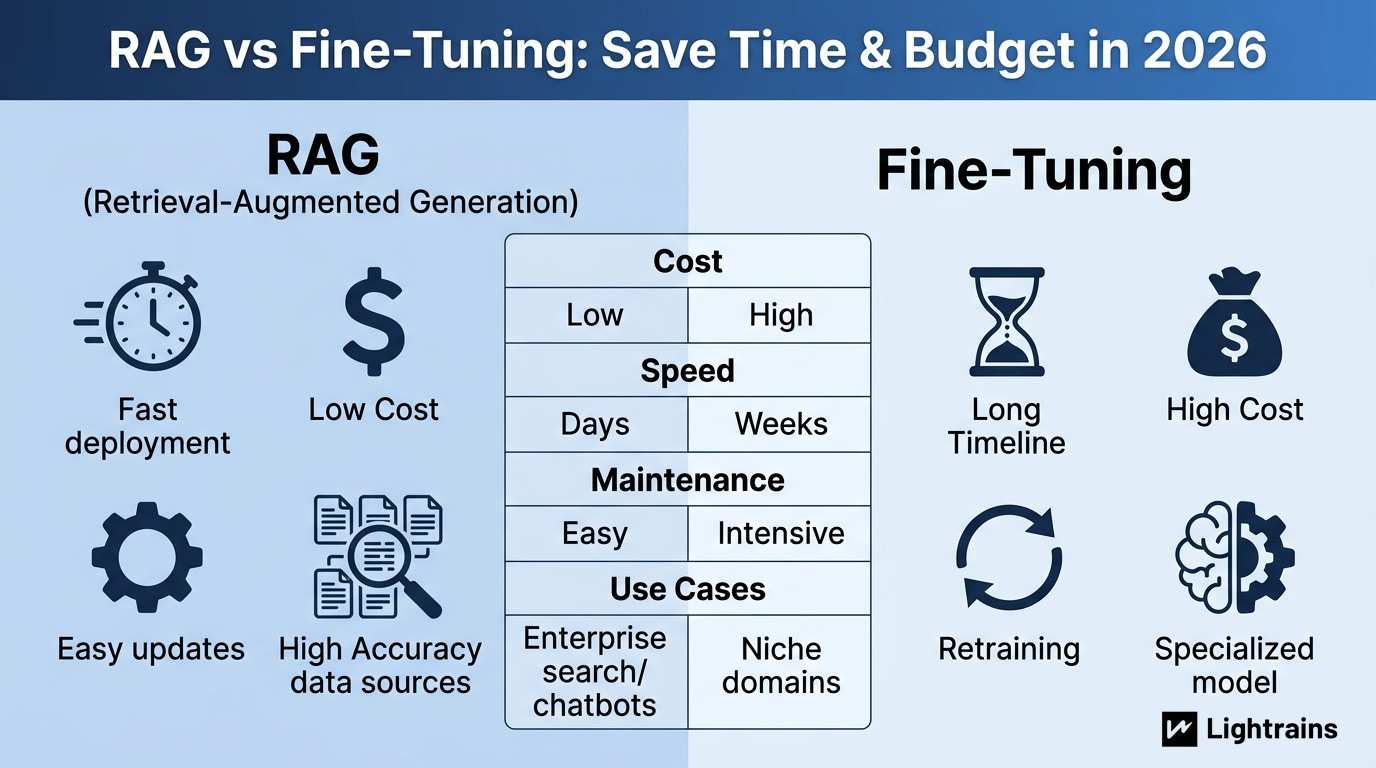
What is RAG?
Retrieval-Augmented Generation connects your LLM to external knowledge. Instead of hoping the model memorize your data, RAG fetches relevant documents at query time and includes them in the prompt.
The flow:
- Chunk your documents into manageable pieces
- Embed chunks into vectors using a model like text-embedding-3-large
- Store vectors in a database like Qdrant or Pinecone
- Retrieve relevant chunks when a user asks something
- Generate a response using the retrieved context
RAG keeps answers grounded in your actual data. Update your knowledge base, and the next query uses the new information. No retraining required.
Why RAG works for enterprise
Your product docs change weekly. Your legal policies update monthly. Fine-tuned models forget this unless you retrain, which costs money and time. RAG simply reindexes new documents and keeps working.
We implemented RAG for a fintech client with 50K daily queries on legal documents. p95 latency stayed under 180ms. The compliance team loved it because they could audit exactly which document chunk every a came from.
What is Fine-Tuning?
Fine-tuning takes a base model and trains it further on your specific data. The model learns your style, terminology, and patterns. After training, it generates responses without needing external context.
The process:
- Collect labeled training data (q-a pairs)
- Prepare your dataset in the right format
- Train on the model (typically 1-48 hours on GPU clusters)
- Evaluate output quality
- Deploy the fine-tuned model
Fine-tuning produces outputs that match your tone and domain precisely. If you need consistent formatting or niche terminology, fine-tuning delivers.
The fine-tuning trade-off
The problem is your data changes. Every product update, policy change, or new feature means collecting more examples and retraining. Training a 70B parameter model costs $10K-50K per iteration. A healthcare client we worked with spent $340K annually just keeping their fine-tuned model current.
Fine-tuning also risks catastrophic forgetting, where the model loses general capabilities while gaining your specific knowledge.
Side-by-side comparison
| Aspect | RAG | Fine-Tuning | Winner |
|---|---|---|---|
| Initial Cost | $5K-20K | $50K-200K | RAG |
| Implementation Time | 2-4 weeks | 8-16 weeks | RAG |
| Updates | Reindex documents | Retrain model | RAG |
| Ongoing Monthly Cost | $500-2K | $15K-40K | RAG |
| Accuracy on Static Data | 85-92% | 90-95% | Tie |
| Accuracy on Changing Data | 88-94% | 40-70% | RAG |
| Hallucination Rate | Low (cite sources) | Moderate-High | RAG |
| Audit Trail | Document-level | None | RAG |
For most enterprise use cases handling dynamic data, RAG wins on total cost of ownership.
When RAG makes sense
Choose RAG if your data changes frequently, you need audit trails, your team lacks ML infrastructure experience, or your budget constrains you to under $20K initial investment.
We recommend RAG for:
- Customer support knowledge bases that update with every product release
- Legal and compliance documents requiring source citations
- Internal search across disparate document repositories
- Technical documentation that changes with each release
A healthcare client using RAG reduced their a citation rate from 34% to 96%. They never had to retrain the model.
When fine-tuning makes sense
Fine-tuning still wins for specific situations:
- Stable domains with rarely changing terminology, like contract law or medical billing codes
- Consistent output formatting required across every response
- Latency-critical applications where external lookups add unacceptable delay
- Limited data scenarios where retrieval has nowhere to fetch from
If you’re building a writing assistant that must match your brand voice exactly, fine-tuning outperforms RAG at the cost of flexibility.
The real cost breakdown
Here’s what we see with actual client implementations:
RAG implementation
- Vector database setup: $2K-5K
- Embedding pipeline: $3K-8K
- Evaluation framework: $2K-5K
- Total initial: $7K-18K
- Monthly infrastructure: $500-2K
Fine-tuning implementation
- Data preparation: $15K-40K
- Training infrastructure: $25K-80K
- Evaluation: $10K-25K
- Total initial: $50K-145K
- Monthly retraining: $15K-40K
A mid-market retail client chose fine-tuning initially. Six months later, they spent more on retraining than their initial build. They switched to RAG and cut AI costs by 67%.
Why Lightrains for RAG implementation
We’ve deployed RAG systems for fintech, healthcare, and legal clients handling millions of queries. Our production RAG pipeline using Qdrant cut p95 latency from 1.2 seconds to 180ms for a legal document search system.
We offer:
- Free RAG readiness assessment
- Vector database evaluation (Qdrant, Pinecone, Weaviate)
- Hybrid search architecture design
- Retrieval quality evaluation frameworks
- Latency optimization
If you’re deciding between RAG and fine-tuning, talk to us. We’ve made this call dozens of times. We can help you choose based on your actual requirements.
This article originally appeared on lightrains.com
Leave a comment
To make a comment, please send an e-mail using the button below. Your e-mail address won't be shared and will be deleted from our records after the comment is published. If you don't want your real name to be credited alongside your comment, please specify the name you would like to use. If you would like your name to link to a specific URL, please share that as well. Thank you.
Comment via email






