
Summary: Gemma 4 E4B (4.5B params, 128K context, native audio/image/text) collapses 3-model stacks into one for edge AI. Fine-tune for ASR, event classification, voice-intent, document agents.
If you are running more than one AI model in production to handle audio, images, and text, this changes everything.
Most enterprise AI stacks look like this: Whisper for speech recognition, a vision model for images, a language model for text. Three endpoints to scale, three failure modes to handle, three bills to pay. And somewhere in the middle, a pipeline that stitches them together and hoping latency stays acceptable.
Google just released Gemma 4 E4B [Google Model Card]. A 4.5 billion parameter multimodal model with native audio, image, and text understanding.
This is the first model that lets enterprises collapse three-model architectures into one deployment. And the fine-tuning capability means you can adapt it to your domain, your data, your specific requirements.
What Makes This Different
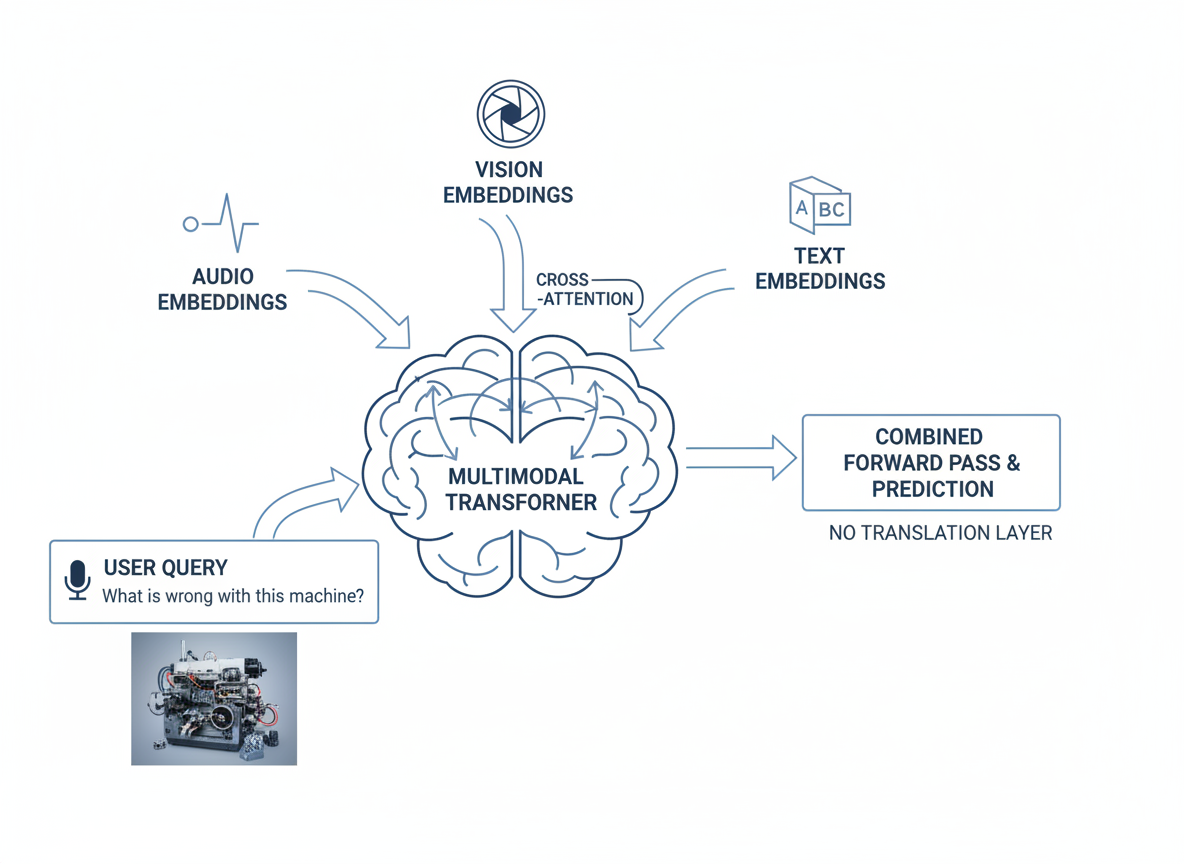
The 300 million parameter audio encoder is baked into the foundation model, not bolted on after. That matters for two reasons.
Cross-modal understanding. When audio, vision, and text are learned together during pretraining, the model develops representations where all modalities attend to each other. Ask “What is wrong with this machine?” and it processes both your audio description and the image of the machine in the same forward pass. No translation layer between modalities.
Single inference path. One model, one endpoint, one latency profile to optimize. You stop managing pipeline complexity and start shipping features faster.
The specs: 128K context window, runs on consumer hardware, fully open weights [Google Model Card].
Gemma 4 Fine-Tuning Use Cases for Enterprise AI
We have been mapping this model against enterprise AI demands across industries. Here is where it actually delivers:
1. Domain-Specific Chatbots
Specialized assistants for finance, legal, or medical sectors that require high adherence to specific industry terminology. Fine-tune Gemma 4 E4B to understand your company’s knowledge base, internal processes, and domain-specific jargon.
Example: A legal AI assistant trained on case law databases that understands “motion to dismiss” vs “summary judgment” and can cite relevant precedents in responses.
2. Structured Output (Function Calling)
Training the model to consistently generate structured outputs like JSON or specific API call formats for agentic workflows. This eliminates the need for post-processing parsers and reduces integration complexity.
Example: A customer service bot that outputs {"action": "refund", "amount": 49.99, "reason": "defective"} directly to your CRM API without any parsing layer.
3. Long-Context Understanding
Fine-tuning the 128K context window model to parse, summarize, and retrieve information from massive documents, PDFs, or technical reports. Extract specific information from entire codebases or legal contracts in one pass.
Example: An insurance claims processor that ingests a 200-page policy document and answers “Does coverage X apply to incident Y?” by referencing specific sections.
4. Multimodal Tasks
Adapting the E4B model for specific image-to-text tasks, such as document OCR, chart interpretation, or UI analysis. Train on your specific document templates or UI designs for higher accuracy.
Example: A manufacturing quality system that reads custom gauge displays, interprets schematic diagrams, and classifies defects from camera feeds all in one model.
5. Multilingual Adaptation
Training specialized models for specific languages, leveraging the 140+ language base. Achieve higher accuracy in low-resource languages or regional dialects where general-purpose models struggle.
Example: A banking chatbot fine-tuned on Hindi financial terminology that accurately explains products in regional dialects spoken across India.
6. Model Distillation
Using a larger model to generate synthetic data, then fine-tuning smaller Gemma 4 versions (E2B/E4B) for efficient, low-latency deployment. Create compact models that retain specialized capabilities.
Example: Generate 10K medical Q&A pairs from GPT-4, then fine-tune E4B to create a lightweight hospital triage assistant that runs on local hardware.
7. Audio & Voice Pipelines
Original use cases: domain-specific ASR, audio event classification, voice-to-intent pipelines. Fine-tune to skip the ASR-to-NLU chain entirely and go straight from voice input to structured output.
Example: A warehouse voice system that understands “Grab the blue bins from aisle three” and outputs {"action": "pick", "item": "blue bins", "location": "aisle-3"} without transcription.
Gemma 4 Fine-Tuning Best Practices
Data Preparation: Create specialized datasets that reflect the desired output format and reasoning style.
Reasoning Control: Mix reasoning examples (75%+) with direct answers if preserving thought capabilities is necessary, or disable it for simple tasks.
Evaluation: Test with tools like the NVIDIA NeMo framework or Hugging Face TRL to verify that specialized capabilities are gained without losing general reasoning.
GGUF Export: Export fine-tuned models to GGUF format for deployment on llama.cpp or Ollama.
Gemma 4 E4B vs Traditional Multi-Model Architecture
| Feature | Gemma 4 E4B | Traditional 3-Model Stack |
|---|---|---|
| Parameters | 4.5B | Whisper (75M) + Vision (1B) + LLM (7B) |
| Context Window | 128K | Varies by model |
| Modalities | Audio + Image + Text | Requires pipeline |
| Latency | Single inference | Chained inference |
| Deployment | Single endpoint | 3+ endpoints |
| Fine-tuning | Full control | Per-model tuning |
The Business Case for Edge
Most enterprise AI teams run three to four separate models to handle what Gemma 4 E4B does in one. That is:
- Three to four inference endpoints to scale and maintain
- Three to four latency profiles to optimize
- Three to four failure modes to monitor
Consolidating to one model cuts infrastructure costs, reduces operational overhead, and simplifies compliance. For regulated industries, on-device processing means audio and images never leave the device. You meet data residency requirements without building privacy infrastructure.
Who This Is For
If you are evaluating on-device AI, you fall into one of these:
- Building customer-facing AI agents that need to process voice and visual input in real time
- Deploying AI at the edge where latency and connectivity are constraints
- Handling sensitive data where privacy regulations prevent cloud processing
- Running cost-sensitive AI operations where consolidating models directly impacts budget
What We Do
We have been fine-tuning multimodal models for enterprise since 2023. We have built production systems that process audio and visual data on edge devices for clients in manufacturing, healthcare, and fintech.
Our offshore AI development team has experience deploying multimodal AI in production environments. We handle the full pipeline from data preparation to edge deployment.
If you are evaluating whether Gemma 4 E4B fits your architecture, we can help you:
- Audit your current AI stack and identify where consolidation delivers cost savings
- Fine-tune a domain-specific model on your data with our infrastructure
- Build a proof of concept for your specific use case in 2-3 weeks
We also offer AI consulting services to help you navigate the model selection and deployment landscape.
Ready to consolidate your AI stack? Talk to our AI team for a technical consultation. We will review your architecture and map where this model delivers value.
Related Services:
This article originally appeared on lightrains.com
Leave a comment
To make a comment, please send an e-mail using the button below. Your e-mail address won't be shared and will be deleted from our records after the comment is published. If you don't want your real name to be credited alongside your comment, please specify the name you would like to use. If you would like your name to link to a specific URL, please share that as well. Thank you.
Comment via email







