
Artificial intelligence has come a long way, evolving from rigid, rule-based systems to highly dynamic models capable of generating human-like responses. However, depending on the goal whether it’s efficiency, specialization, or real-time adaptability different optimization strategies come into play. In this post, we’ll take a deep dive into Distillation, Fine-Tuning, and Retrieval-Augmented Generation (RAG), analyzing their strengths, real-world applications, and how they can be effectively implemented in JavaScript and Node.js.
1. Model Distillation: The Art of Making AI Leaner
What is Distillation?
Think of distillation as passing knowledge from a seasoned expert (teacher model) to a more agile, lightweight understudy (student model). The student mimics the expert’s behavior, capturing essential insights while being significantly more resource-efficient.
Where It Shines
Lightweight AI on Mobile & IoT: Running AI models on devices with limited processing power.
Speed-Driven Applications: Reducing inference latency without sacrificing too much accuracy.
Cost-Efficient AI Deployment: Minimizing cloud computing costs by using smaller models.
How to Implement Model Distillation in Node.js (TensorFlow.js)
const tf = require('@tensorflow/tfjs-node')
async function createStudentModel() {
const model = tf.sequential()
model.add(
tf.layers.dense({ inputShape: [10], units: 32, activation: 'relu' })
)
model.add(tf.layers.dense({ units: 16, activation: 'relu' }))
model.add(tf.layers.dense({ units: 10, activation: 'softmax' }))
model.compile({
optimizer: tf.train.adam(),
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
})
return model
}
2. Fine-Tuning: Elevating AI to Expert Level
What is Fine-Tuning?
Imagine taking a world-class pianist and training them to master jazz improvisation. Fine-tuning follows the same philosophy—it takes a pre-trained model and refines it using domain-specific data, making it an expert in specialized tasks.
Where It Excels
Industry-Specific AI: Tailoring models for healthcare, finance, Retail, or legal industries.
Adaptability: Quickly adjusting a general AI to a particular use case with minimal data.
Improving Model Performance: Boosting accuracy by focusing on specialized training.
Fine-Tuning with TensorFlow.js in Node.js
async function fineTuneModel(model, newData, newLabels) {
await model.fit(newData, newLabels, { epochs: 5, batchSize: 10 })
console.log('Fine-tuning complete.')
}
3. Retrieval-Augmented Generation (RAG): AI that Stays Updated
What is RAG?
Traditional AI models are static—they don’t know about world events post-training. RAG breaks this limitation by retrieving relevant documents from a vast knowledge base before generating responses, ensuring that AI stays up-to-date with real-world knowledge.
Best Use Cases
AI Chatbots with Current Knowledge: Keeping virtual assistants informed about company policies or breaking news.
Legal & Research Assistants: Pulling legal precedents or the latest scientific findings before answering questions.
Dynamic Customer Support: Reducing the need for frequent AI retraining by fetching real-time information.
Node.js Implementation Using APIs & Vector Databases
const axios = require('axios')
async function retrieveAndGenerate(query) {
const response = await axios.post('https://openai.com/api/retrieve', {
query
})
const retrievedDocs = response.data.documents
const generatedResponse = await axios.post(
'https://openai.com/api/generate',
{ prompt: `Using: ${retrievedDocs}, answer: ${query}` }
)
return generatedResponse.data.text
}
Picking the Right AI Optimization Technique
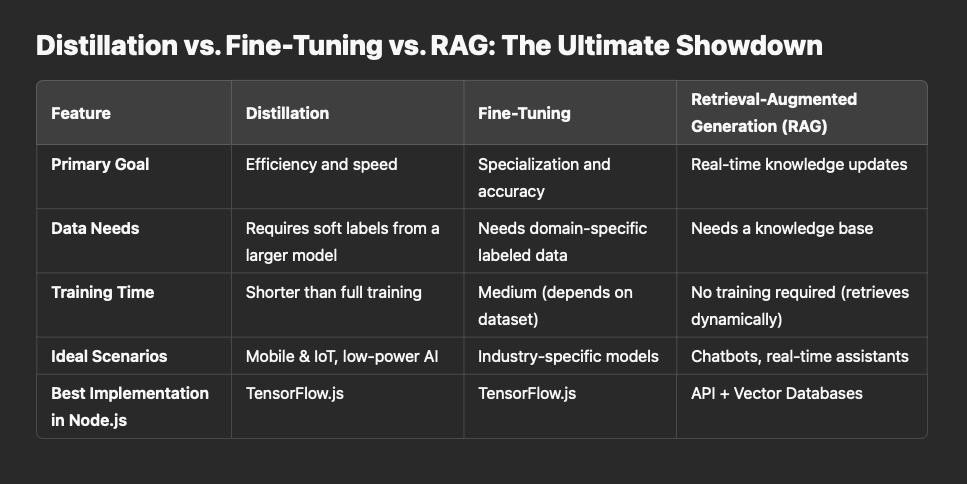
Choosing between distillation, fine-tuning, and RAG depends on your end goal:
Distillation: Best for optimizing model efficiency and performance, making AI lightweight and fast.
Fine-Tuning: Ideal for enhancing AI with domain-specific knowledge and improving accuracy.
RAG: The ultimate choice for keeping AI models current without frequent retraining.
By leveraging JavaScript and Node.js, developers can seamlessly integrate these techniques into their AI-powered applications, creating smarter, more efficient, and more relevant AI solutions.
Ready to Optimize Your AI Models?
At Lightrains, we specialize in developing and optimizing AI solutions tailored to your business needs. Whether you need help with model distillation, fine-tuning, or implementing RAG architecture, our team of expert AI developers can guide you through the entire process.
Our AI consulting company has deployed optimized models across edge devices, enterprise cloud, and hybrid environments. Let’s work together to create efficient, powerful AI applications that give your business a competitive edge.
Contact us today to discuss your AI development needs and discover how we can help transform your ideas into reality.
This article originally appeared on lightrains.com
Leave a comment
To make a comment, please send an e-mail using the button below. Your e-mail address won't be shared and will be deleted from our records after the comment is published. If you don't want your real name to be credited alongside your comment, please specify the name you would like to use. If you would like your name to link to a specific URL, please share that as well. Thank you.
Comment via email







