
Production AI agents stop being experiments the moment finance asks for a forecast. Most teams are not ready for that conversation.
By 2026, agents moved from demos to production support, sales, and operations. That shift introduced a new failure mode: runaway costs. Tool calls, recursive reasoning, large prompt windows, and fallback loops all drive token spend. Without explicit AI agent budgets, a single workflow can burn more in a day than a traditional software feature costs in a month.
This framework is for CXOs and engineering leads who need to control costs before hitting production. Set budgets. Enforce guardrails. Observe spend. Do not strangle the autonomy that makes agents valuable. Tie cost discipline to reliability metrics so you can answer “Will this ship on budget?” with data instead of hope.
Why AI agent budgets are becoming a board-level concern
Enterprises adopted AI agents faster than they adopted governance for them. A 2026 VentureBeat Pulse survey found that 79% of enterprise organizations already took a real financial or operational hit from autonomous agents, often through shadow AI run by employees outside anyone’s oversight. Uber reportedly burned through its entire 2026 AI coding budget in four months after Claude Code adoption reached 84% of its engineers. Microsoft canceled most internal Claude Code licenses in its Windows and Microsoft 365 division.
These stories reveal a pattern. Deployment is moving faster than monitoring, budgeting, and policy. You need controls that match the speed of adoption, not a research project. You need enforceable limits plus visibility into whether those limits are working. When Lightrains builds production AI agent systems for enterprise clients, we start with budget tiers before writing the first tool call.
Set token budgets at the workflow level
A blanket token limit for every agent is too blunt. Legal document review or financial reconciliation requires more output than customer support triage. Order status checks should never spend heavily. Map your workflows into tiers. High-complexity workflows get higher budgets. Low-complexity ones get tight budgets with fast fail.
Set three numbers per tier: a hard maximum, a warning threshold, and a fallback trigger. The hard maximum stops the run. The warning threshold triggers a checkpoint. The fallback trigger routes the request to a cheaper model or a human queue. Derive these from actual usage, not guesswork. Run a two-week observation window with logging but no hard limits. Measure p50, p90, and p99 token counts. Set limits at roughly the p99 level, with automatic escalation if p99 expands over time.
Tool-call limits prevent infinite loops
Agents fail by looping. A tool call returns an ambiguous result. The agent retries the same tool. The retry consumes tokens, time, and money. Tool-call limits are the simplest effective safeguard. Set a maximum number of tool calls per agent run. Three to five calls handle most workflows. Ten is the absolute ceiling. When the agent reaches the limit, stop, log the failure, and hand off to a human or fallback workflow.
Pair tool-call limits with timeout rules. Long-running tool calls (database queries, external API polling) need strict timeouts. Returning an error after a timeout is cheaper than returning a timeout after twenty retries. Instrument every tool call with duration and outcome metrics. Build a dashboard that shows calls by latency, error rate, and retry count. If one tool accounts for half your agent spend, investigate before it becomes your top line item.
Fallback policies protect the budget and the user
An agent that hits a limit should not just fail. It should follow a fallback policy. The weakest policy is “return an error message.” A better policy is “retry with a cheaper model or smaller context.” A stronger policy is “hand off to a human with full context.” The best policy is hybrid: try a cheaper model, then escalate if confidence drops below a defined threshold.
Fallback policies need confidence scoring. Every agent response should include a confidence score. If confidence is low and the budget is nearly exhausted, stop. This is a cost control and a reliability control. Users prefer a fast handoff over a slow, hallucinated answer. Set confidence thresholds by workflow. Customer-facing workflows need higher confidence than internal research workflows. Document the thresholds. Make them auditable.
Observability turns mystery into measurement
You cannot manage what you cannot see. Most enterprises lack observability into AI agents. VentureBeat Pulse data shows that just one in ten enterprises has automated monitoring capable of catching AI model drift or failure in production. That gap explains why agent costs surprise finance teams.
Start with four metrics: token spend per run, tool-call count per run, success rate versus fallback rate, and latency p99. Correlate these with workflow type, model version, and time of day. You will likely see patterns: morning spikes, specific workflows that grow expensive, models that cause higher retry rates. Each pattern is a place to tighten controls or reroute traffic.
For a deeper look at how budget controls interact with agent loop design, read our post on production AI agent loop engineering.
Alternatives to tight controls
Some teams resist strict agent budgets. They argue constraints reduce agent usefulness or slow development. That is a valid concern. The alternative is to select tasks where agents add value without open-ended reasoning. Invoice parsing, structured data extraction, and ticket triage are good candidates. Open-ended creative tasks (marketing copywriting) are bad candidates for expensive autonomous loops.
Lightrains has seen better outcomes when clients treat agents as narrow, supervised tools rather than general-purpose employees. If you need broad autonomy, invest in a model-routing layer that can switch between closed frontier models and open-weight alternatives on your own infrastructure. That hedges both cost and vendor risk.
What does not work
Unlimited retries do not work. They guarantee runaway costs. Model-only cost controls do not work. Input token pricing changes, and output tokens usually cost more. Single-model dependency does not work. Closed APIs can be pulled offline for regulatory reasons (as seen with Claude Fable 5 in June 2026). Treating agent spend as “another cloud bill” does not work. Agent costs are more volatile and harder to predict than infrastructure costs. They need their own budget line, their own alerts, and their own review cadence.
How to use this framework
Pick one pilot workflow. Set a token budget based on observed p99 usage. Set tool-call limits and confidence thresholds. Turn on fallback to a human or cheaper model. Measure for two sprints. Review every cost outlier. Adjust budgets quarterly. If the pilot succeeds, expand to one additional workflow. Do not roll this out as a blanket policy. Treat it as guardrails that tighten as your agent population grows.
Here is the budget flow in practice:
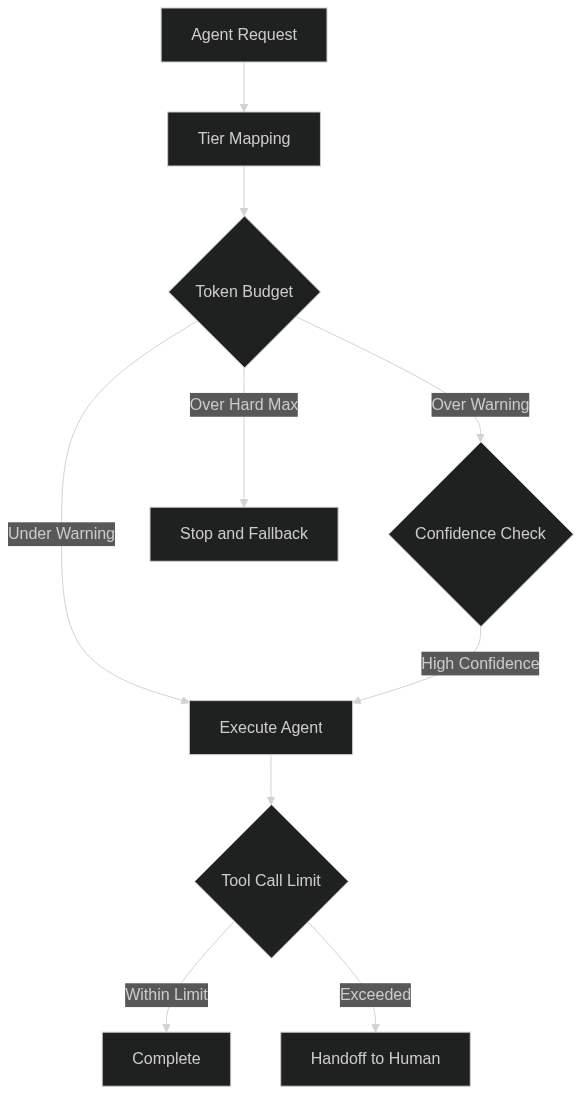
If you are budgeting AI agents in 2026, you are already behind the curve on what these systems can consume. You do not have to choose between autonomous AI and predictable costs. You need the right limits, right metrics, and right fallback policies.
Lightrains builds and audits production AI agent systems with explicit cost controls and fallback policies. If you want to review your agent architecture for runaway costs, talk to our AI, ML and CV Development team.
This article originally appeared on lightrains.com
Leave a comment
To make a comment, please send an e-mail using the button below. Your e-mail address won't be shared and will be deleted from our records after the comment is published. If you don't want your real name to be credited alongside your comment, please specify the name you would like to use. If you would like your name to link to a specific URL, please share that as well. Thank you.
Comment via email






